To enable reliable long-term interaction, LLM agents require a memory system that can
faithfully store, efficiently retrieve, and deeply reason over accumulated
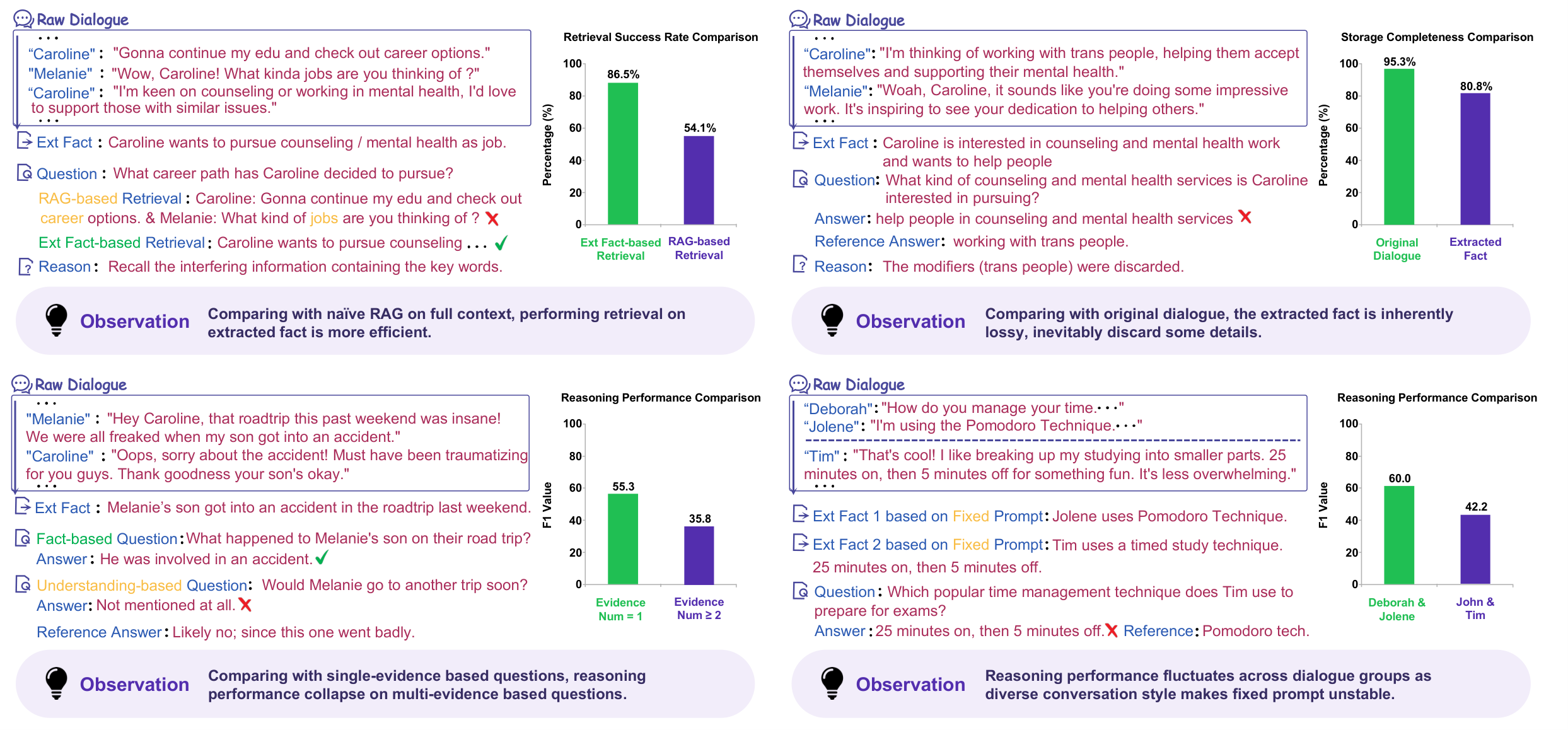
dialogue history. Most existing methods adopt an extracted-fact paradigm: handcrafted
static prompts compress raw dialogues into atomic facts, which are then stored, matched,
and injected into downstream reasoning.
Such fact-centric designs inevitably discard fine-grained details in the
original dialogue and fail to support deep reasoning over scattered
isolated facts. Moreover, static prompts cannot maintain consistent extraction granularity
across diverse dialogue styles.
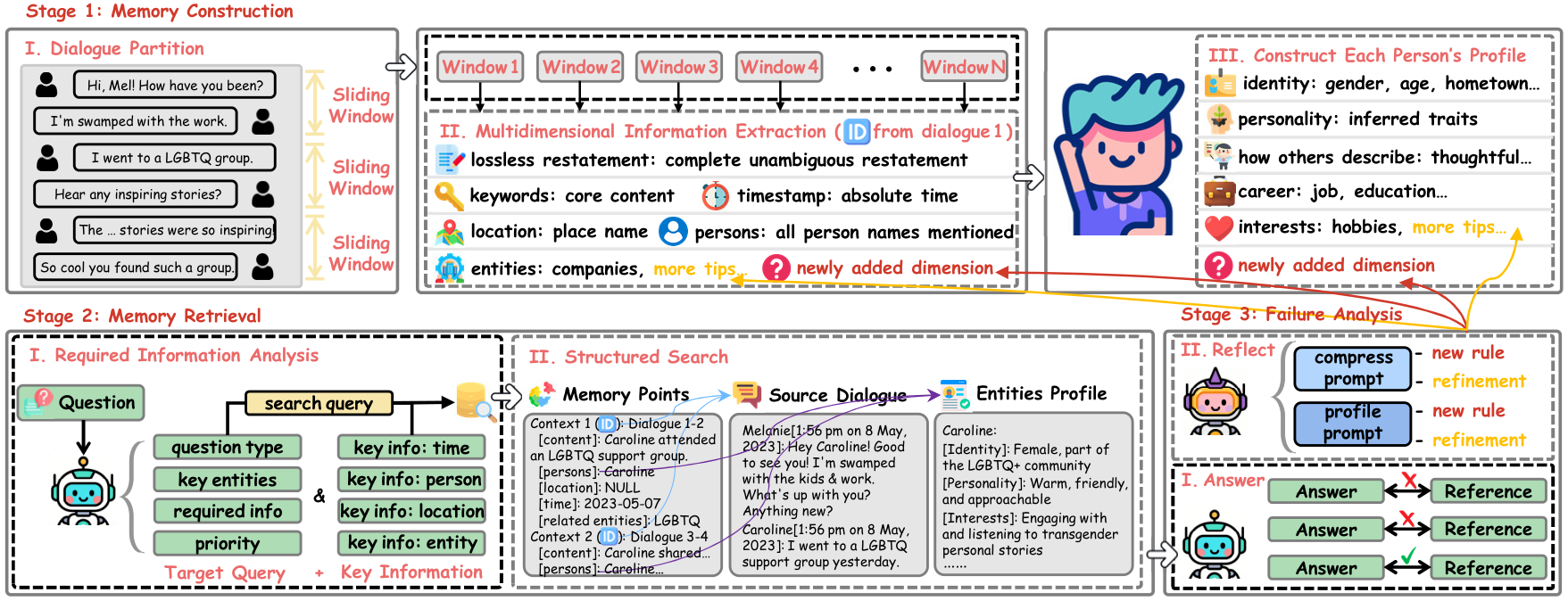
We propose TriMem, which maintains three coexisting representation
granularities: raw dialogue segments anchored by source identifiers for storage fidelity,
extracted atomic facts for efficient retrieval, and synthesized profiles that aggregate
dispersed facts into holistic semantic understanding for deep reasoning. We further adopt
TextGrad-based prompt optimization to iteratively refine extraction and
profiling prompts via response-quality feedback, achieving lifelong evolution without any
parameter updating. Extensive experiments on LoCoMo and PerLTQA across multiple LLM
backbones demonstrate that TriMem consistently outperforms strong memory baselines.